| Die Zukunft - Programmierbare Shader-Sprache |
|
Was ist eine Shader-Sprache / Real-Time Shading Language (RTSL)? Wie in meinem Artikel zum Thema OpenGL & DirectX beschrieben, gibt es seit DirectX 8 jeweils eine Sprache um Vertexdaten (3D-Koordinaten) und Pixeldaten zu manipulieren. Die Vertex Sprache ist recht einfach, da es hier nur um die Manipulation von Vektoren geht und kann, wenn nicht vom GPU beschleunigt, auch von der CPU übernommen werden. Die weit größeren Möglichkeiten bietet aber die Shader Sprache. Mit ihrer Hilfe können theo. jedem Pixel eigene math. Operationen zugewiesen werden. Somit sind eine nahezu unendliche Menge an Operationen möglich und der Fantasie kaum Grenzen gesetzt. Allerdings liegt hier auch wieder ein Problem, den die Shaderarbeiten können nicht oder nur sehr langsam vom CPU ausgeführt werden. Also definierte man in DX8 die Pixel Shader - Version 1.0. Schnell wurde aber klar, dass das nicht der Weisheit letzter Schluss war, den NVIDIA und ATI hatten verschiedene Ansätze in ihrer Hardware implementiert. So folgten Version 1.1 bis 1.4. Weiteres dazu hier . Da sich die Hardware immer unterscheiden wird, muß also eine einheitliche Sprache her. |
|
Stand der Technik (05.09.2001)
Die heutige Hardware (DirectX 8.0+) ist zu folgendem fähig:
Daraus ergeben sich folgende Nachteile:
|
|
Was würde eine Shader-Sprache bringen?
Vorteile:
mögliche Nachteile:
|
|
Klingt recht komplex, gibt es da schon was?
Ja, natürlich. Quake 3 benutzt eine eigene Shader Scriptsprache,
hier ein kleines Beispiel:
textures/testsurface Vertexdaten (Farbe, Position, Texturekoordinaten) können ebenfalls geändert und erzeugt werden. Die einzelnen Stages werden dann auf verschiedene (oder einen, je nach HW) Renderingdurchläufe umgelegt. Das Stanford Real-Time Programmable Shading Project ist jedoch wesentlich besser als Beispiel geeignet, da es nicht speziell für ein Spiel o.ä. entwickelt wurde und somit wesentlich vielseitiger einsetzbar ist. |
|
Das Stanford Real-Time Programmable Shading Project
Microsoft's Shading Modell in DirectX 8 ersetzt Teile der traditionellen
nicht-programmierbaren Rendering Pipeline mit einer programmierbaren Einheit,
welche über Register gesteuert wird. Anstatt die Programmierbarkeit
durch mehrere Durchläufe zu erweitern, wird die Programmierbarkeit auf
innerhalb eines Durchlaufes beschränkt. Als Resultat behandelt dieses
Modell einen Durchlauf als eine Serie von mehreren einfachen Instruktionen,
ganz im Gegensatz zum SIMD Prozessor Modell des Stanford Real-Time Programmable
Shading Projektes, welches einen Durchlauf als eine komplexe Instruktion
betrachtet.
In DirectX 8 werden Vertex- und Pixelmanipulationen getrennt betrachtet. Für beide gibt es getrennte Sprachen. Für die Pixelmanipulation verwendet man standard Texturekombinationsbefehle, welche auf 8 (< PS1.4) pro Durchlauf beschränkt sind, während NVIDIA's OpenGL Extensions wesentlich mehr Möglichkeiten bieten. Es gibt 2 Hauptunterschiede zwischen dem programmierbaren Vertex-/Pixel-Verarbeitungs Modell von DirectX 8 und der SIMD Prozessor basierten Abstraktion.
Diese zwei Vorteile haben die Macher dazu bewogen, sich dieses Modell näher anzusehen. Weiterhin haben sie Microsoft's und NVIDIA's Ansatz in dreierlei Hinsicht erweitert:
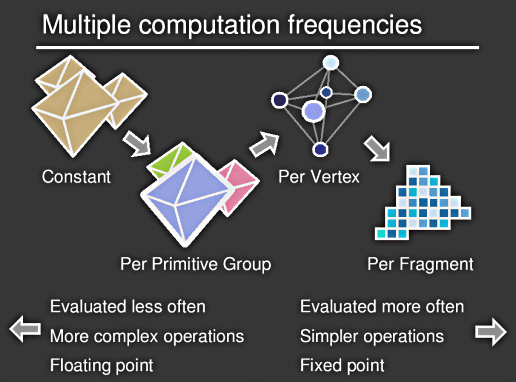
Das System setzt auf OpenGL auf und abstrahiert die Grafikpipeline als einen SIMD Prozessor. SIMD (single instruction mutliple data - eine Instruktion wird auf mehrere Daten angewendet -> komplexe Instruktion)
Features:
Dies wird dann, unter Verwendung einer abstrahierten OpenGL Pipeline, kompiliert. 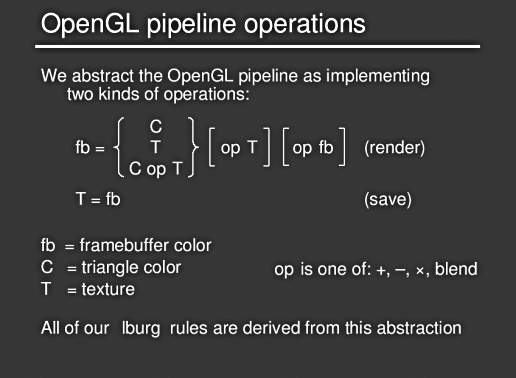

Variablen:
Operationen:
Hier ein Beispiel: 
Konstruktion des Kegels (stimmen nicht mit den Renderingdurchläufen überein, da manche Schritte in einem Durchlauf erledigt werden!)
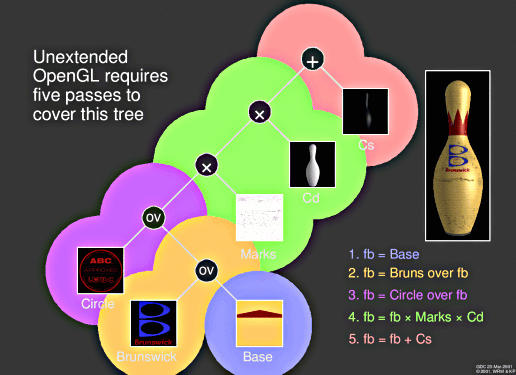
OpenGL, welches keine Extensionen benutzt braucht also 5 Renderingdurchläufe, bis das Bild fertig ist. |
|
Systemüberblick
Hier eine Übersicht des gesamten Systemes:
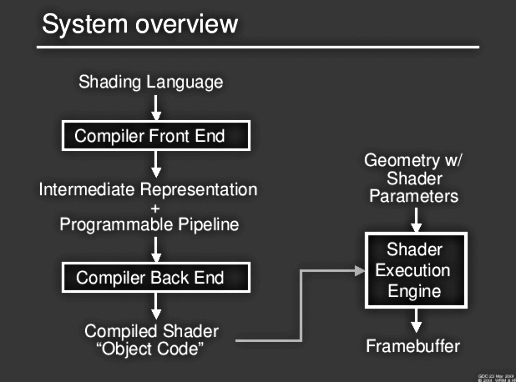
Wie man sieht, muss die Shader-Sprache einige Stufen durchlaufen. Der Aufbau gleicht einer "normalen" Programmiersprache, welche kompiliert wird und als Objektcode der CPU übergeben wird. Intermediate representation:
Programmable Pipeline: 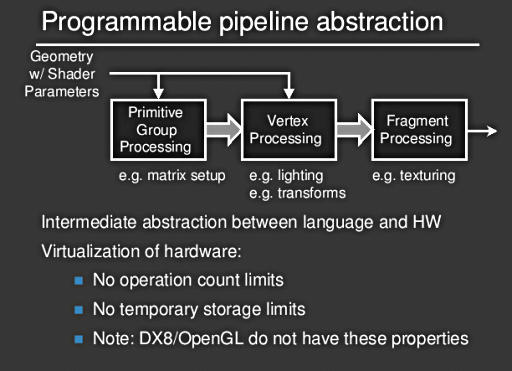
Hier wird die Hardware virtualisiert, das bedeutet, es gibt keinerlei Beschränkungen hinsichtlich der Anzahl der Operationen oder Variablen. (wie die Programmiersprache C im Vergleich zu x86 Assembler) Weder OpenGL, noch DirectX 8 erfüllen diese Voraussetzungen. Leider müssen zur Zeit noch ein paar Beschränkungen beachtet werden:
Front end compilation (drei Schritte):
Back end compilation:
So sieht der Kompilierungsvorgang aus: 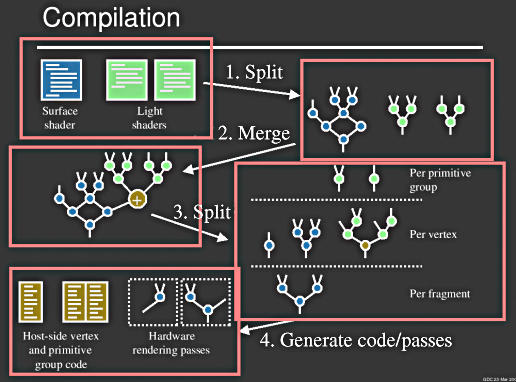
Es werden verschiedene Arten von Code erzeugt, je nachdem, zu welchem Teil er Pipeline er gehört und wo er ausgeführt wird.
Fragment Processing: 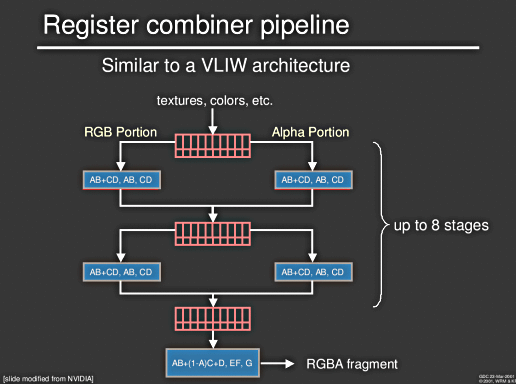
VLIW (Very Long Intruction Word - viele Befehle in einem 64/128/... Bit breitem Block) 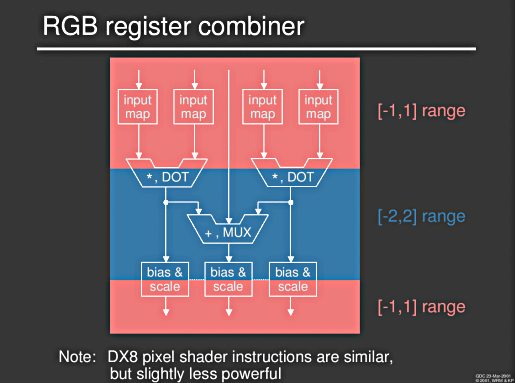
Hier wurd als Beispiel NVIDIA's GF3 OpenGL Extension (NV_register_combiner) benutzt. Man könnte dieses Back end aber auch ohne große Probleme so umschreiben, dass es die DirectX 8 Pixel Shader oder pures OpenGL 1.1 benutzt. Natürlich sind mit beschränktem Funktionsumfang auch nicht alle "Effekte" nutzbar. 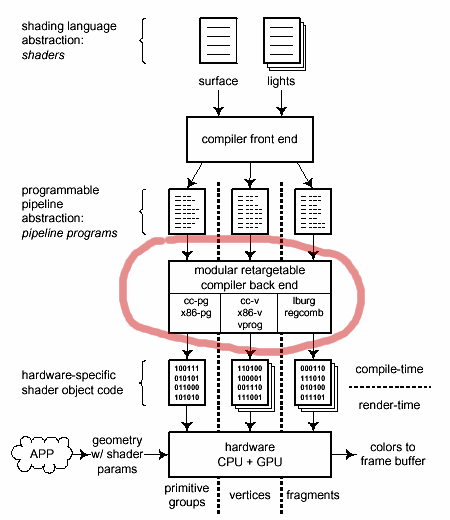
Hier sind sehr schön die austauschbaren Back ends der dreiteiligen Pipeline zu sehen. Für jede Stufe (Group / Vertex / Fragment) wurden mehrere Module geschrieben. Somit ist es sehr einfach, neue Hardware zu implementieren. Man muss einfach nur ein entsprechendes Modul schreiben. Die Zukunft hat also begonnen, eine funktionierende Version (Windows/Linux) kann man sich downloaden. Die Entwicklung dauerte 18 Monate und besteht aus etwas 45000 Codezeilen. Hier noch schnell 2 Bilder, die auf einer GeForce 3 entstanden: 
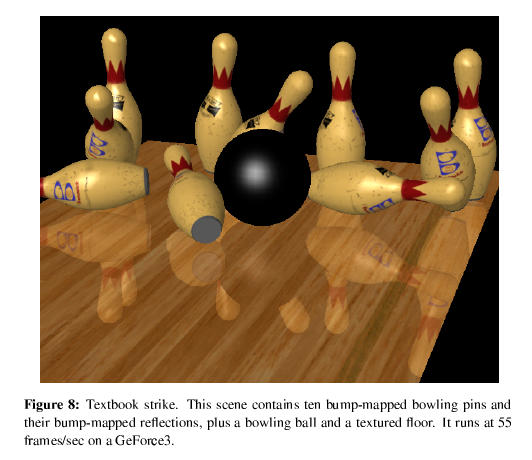
|