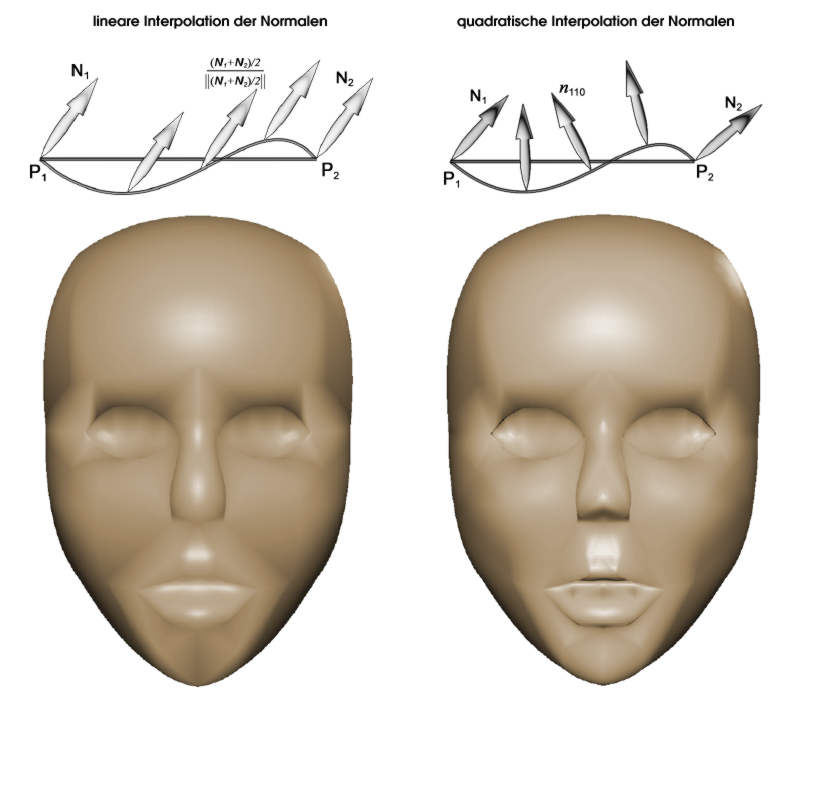
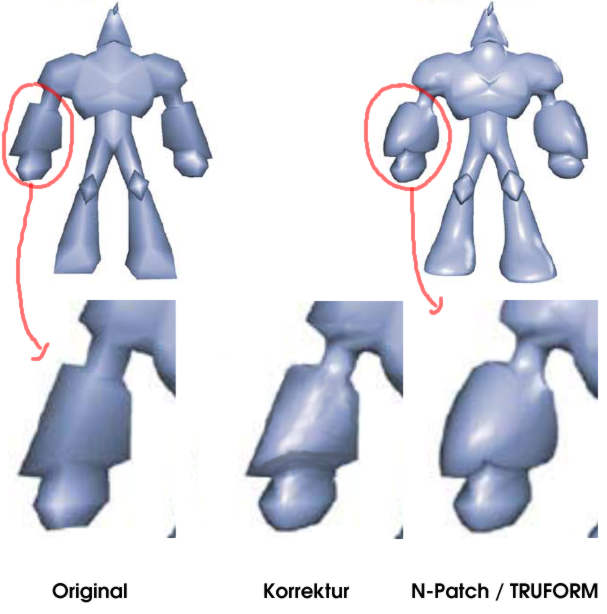
|
Warum High Order Surfaces - Dreiecke reichen doch?
Bis Quake 3 auf dem Markt erschien wurden alle 3D-Level aus 1,2,3...x
eckigen Polygonen zusammengesetzt. Meistens also Punkte, Linien, Dreiecke
und Vierecke. Flächen die mehr als 4 Ecken besaßen, wurden
aus Dreiecken zusammengesetzt, das hatte mathematische Gründe, da
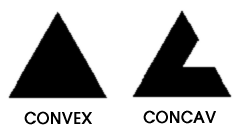
viele Berechnungen mit einem Dreieck am einfachsten sind - sie sind immer
convex.
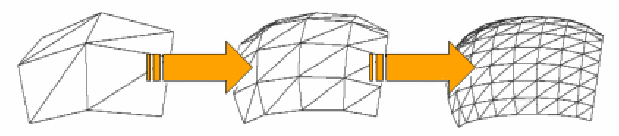
3D-Objekte werden aus vielen kleinen Dreiecken zusammengesetzt,
denn je feiner ein Objekt in Dreiecke unterteilt ist, desto besser werden
Rundungen und Bögen auch als solche erkannt. Mehr Dreiecke bedeutet
auch mehr Arbeit für die CPU, da diese ja die Eckpunkte transformieren
muss (Objekt-Koordinatensystem -> Welt-Koordinatensystem
-> Kamera-Koordinatensystem -> Bildschirm-Koordinatensystem.
Leider hat die CPU auch noch andere Dinge (KI, Kollisionsabfrage, Soundausgabe,
Netzwerkcode, ... zu erledigen, deshalb sollte man die Anzahl der Dreiecke
nicht zu hoch ansetzen, da sonst die Framerate unter 25 Bilder pro Sekunde
fällt, was zu ruckelndem Spielablauf führt.
Als NVIDIA mit ihrem Geforce 256 hardwarebeschleunigtes T&L
( Transformation & Beleuchtung einführen, war die Euphorie
groß. Endlich konnte man hochdetailliert Polygonobjekte verwenden,
den von nun an wurde die gesamte Transformationsarbeit vom Grafikchip
(GPU erledigt. Nebenbei erledigte er auch noch die Belechtung, die somit
zwar nicht viel schneller wurde (keine parallele Berechnung mehrere Lichtquellen,
aber wenigstens genauer. Somit hätte es nur eine kurze Zeitspanne
dauern müssen, bis die T&L Einheit richtig ausgenutzt worden wäre
und es genug Spiele auf dem Markt gäbe, die mit Polygonen nur so protzen.
Ganz so einfach, wie NVIDIA's Marketingabteilung uns das machen
wollte, ist es leider nicht.
Hierzu einen kleine Rechnung:
|
Daten (jew. 4 Floats = 16 Bytes
|
Minimum (in Bytes
|
Durchschnitt (in Bytes
|
Maximum (in Bytes
|
|
Vertex-Daten (xyzw
|
3*4
|
4*4
|
*
|
|
Flächennormale
|
3*0
|
3*4
|
*
|
|
Texturekoordinaten (uvwq
|
3* 0
|
2*4*2(bei 2 Texturen
|
*
|
|
Farbparameter (rgba
|
3* 0
|
4*4
|
*
|
|
Gesamt pro Eckpunkt
|
12
|
60
|
*laut DirectX 8 insgesamt max. 16 Einträge
(jew. 4 Floats pro Vertex
256
|
|
Gesamt pro Dreieck
|
36
|
180
|
768
|
Maximale Leistung, verschiedener GPU's (Herstellerangaben:
Geforce 256 - 15 Mio / Dreiecke (120 Mhz
Geforce 2 GTS - 25 Mio / Dreiecke (200 Mhz
Geforce 2 ULTRA - 31 Mio / Dreiecke (250 Mhz
Geforce 3 - keine offiziellen Angaben, weder auf der Homepage, noch
in PDF's (2x-5x Leistung der Geforce 2 - ca. 50 Mio / Dreiecke!!! (200
Mhz
Radeon 30 Mio / Dreiecke (183 Mhz
Radeon 8500 75 Mio / Dreiecke (250 Mhz
Testsystem: Duron 1000(7,5*133, Geforce 2 Pro 4xAGP - DirectX
8 SDK - Optimized Mesh Demo (46464 Dreiecke aus 23232 Vertices pro Objekt,
16 solcher Objekte
Die Berechnungen erfolgten mit einer Lichtquelle, ein Vertex bestand
aus X,Y,Z, Normalenverktoren und Texturekoordinaten, also 32 Bytes.
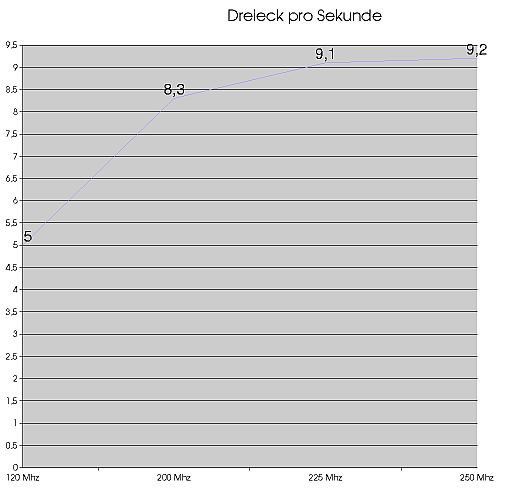
Da die Geforce 256 T&L Einheit genau die gleiche wie beim
Geforce 2 GTS ist, habe ich die Geforce PRO auch mal mit 120 Mhz betrieben.
Irgendwie sieht mir das nicht nach den versprochenen Werten aus. Bei 120
Mhz, also Geforce 256 Niveau kommt die GPU gerade auf 5 Mio. Dreiecke -
versprochen waren aber 15 Mio! Bei der Geforce 2 GTS genauso, 8,3 Mio,
versprochen waren 25 Mio. Haben wir da irgendetwas übersehen?
JA!
Nicht nur wir, sondern auch viele Entwickler von Spielen machten/machen
diesen Fehler!
Es wurde ganz einfach vergessen, die Dreiecke in Cache freundlicher
Reihenfolge an den GPU zu übergeben.
Vertex Cache (ein Vertex im Cache spart prefetch (holen und T&L
Zyklen!:
Geforce 256 - 16 Einträge
Geforce 2 GTS - 16 Einträge
Geforce 3 - 24 Einträge
Radeon 30 Mio - Hersteller konnte keine Angaben machen
Radeon 8500 75 - Hersteller konnte keine Angaben machen
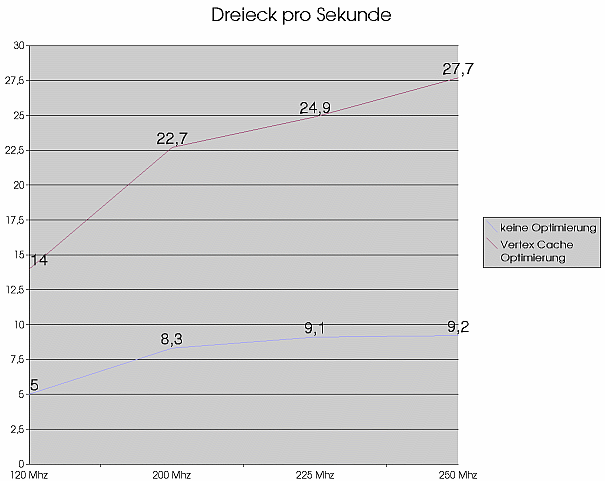
|
Geforce 2 Mhz
|
Minimum
|
Maximum
|
Herstellerangabe
|
|
120
|
5
|
14
|
15
|
|
200
|
8,3
|
22,7
|
25
|
|
225
|
9,1
|
24,9
|
-
|
|
250
|
9,2
|
27,7
|
31
|
Es ist deutlich zu erkennen, dass die T&L Werte jetzt schon
eher an die Herstellerangaben heranreichen. Zur Sicherheit, habe ich
die Anzahl der Lichtquellen mal erhöht, allerdings nur bei 200 Mhz
GPU Takt. Das Ergebnis:
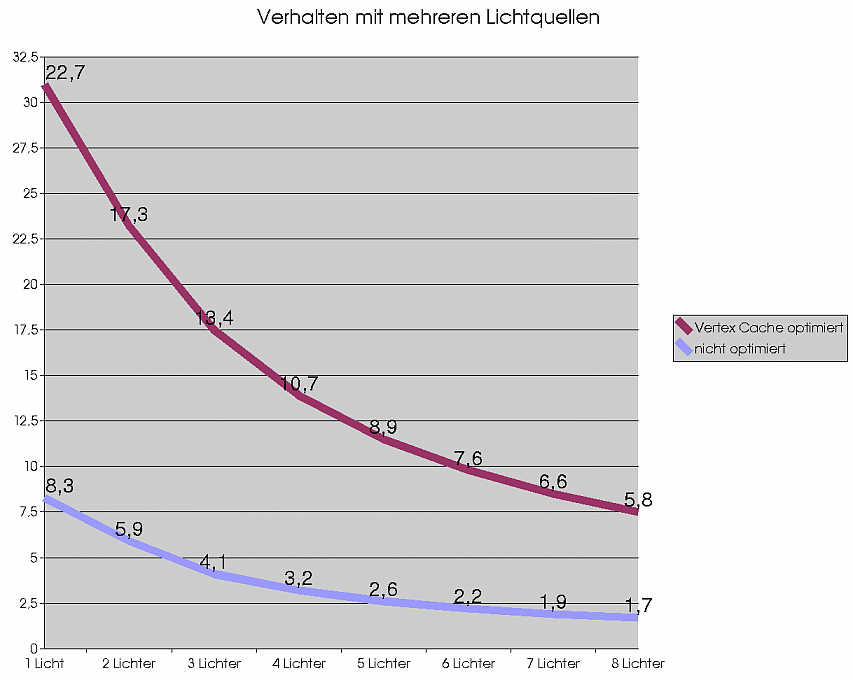
Wie sich der Geforce 3, die Radeon und die Radeon 8500 hier verhält
konnte ich leider nicht testen. Wenn jemand ein Testexemplar übrig
hat, einfach ne Mail
an mich. Mit 0 Lichtquellen steigt der Durchsatz kaum noch an,
deshalb wurde es hier nicht mit aufgeführt.
Das Lichtquellenproblem ist aber recht einfach zu umgehen, einfach
nur eine oder zwei verwenden. Dieses Beleuchtungsmodell hat sowieso an
Bedeutung verloren, da heute und in Zukunft die Beleuchtung mit den Pixel
Shadern erledigt wird.
Eine effiziente Anordnung und Vermeidung von Eckpunkten erreicht
durch Fans und Strips.
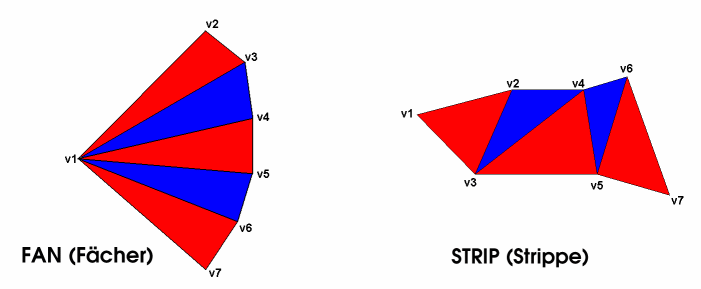
In unseren Benchmarks haben wir ein Modell mit 46464 Dreiecken
und 23232 Vertices verwendet. Dieses Mesh-Objekt ist optimiert, da auf
jedes Dreieck, statistisch gesehen, gerade einmal 0.5 Eckpunkte kommen.
Ohne Optimierung wären es 3 Eckpunkte pro Dreieck.

Bei 32 Byte pro Eckpunkt und 27,7 Mio. Dreiecken (3*27,7 Eckpunkte
käme man so auf 2659,2 MBytes (2,7 GB pro Sekunde.
1. Flaschenhals
Der RAM - außer RDRAM mit zwei, oder mehr Kanälen schafft
kein anderer RAM diese Bandbreiten.
2. Flaschenhals
Der BUS - selbst AGP 8x würde nur etwas mehr als 2000 MBytes
befördern und Texturedaten benötigen auch noch Bandbreite.
Zum Glück benötigt unser Objekt nur knapp ein 443,2
MBytes an Bandbreite. Da reicht AGP 2x.
|
|
Bandbreite Chipsatz zum RAM / BUS (MByte/s
|
|
PC100 RAM
|
800
|
|
PC133 RAM
|
1064
|
|
RDRAM (ein Kanal / RDRAM (zwei Kanäle
|
1600 / 3200
|
|
PC200 DDR RAM / PC266 DDR RAM
|
1600 / 2128
|
|
PCI (33Mhz
|
132
|
|
AGP 2x
|
528
|
|
AGP 4x
|
1056
|
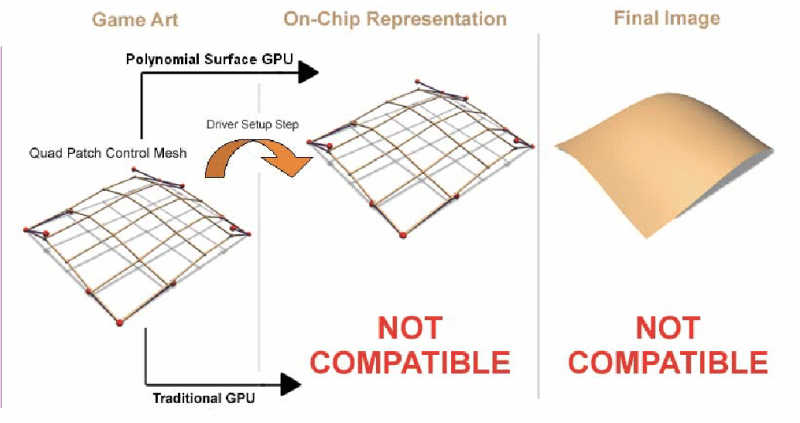
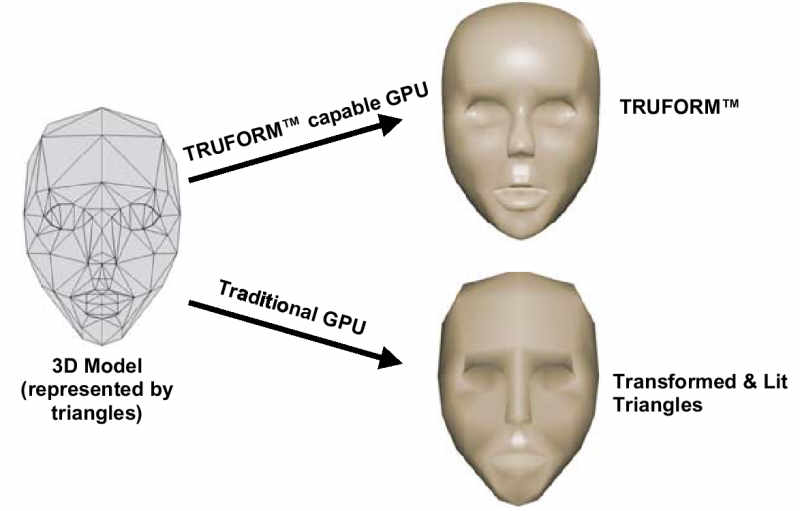
Der beste Eckpunkt ist der, den man nicht übertragen muss. Genau
hier setzen High Order Surfaces an.
|