
| ASUS V8200 Deluxe |
|
Lightspeed Memory Architektur
Da die Bandbreite (Speicher und AGP-Bus) das größte Problem
heutiger Grafikkarten ist, musste sich NVIDIA etwas einfallen lassen, da
der GeForce 3 den selben Speicher wie die GeForce 2 ULTRA benutzt und somit
auch "nur" 7,36 GB/s besitzt. Heraus kam die Lightspeed Memory Architekur,
welche aus Folgende Teilen besteht:
Crossbar Memory Kontroller
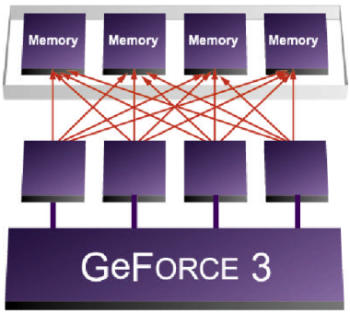
Das Speicherinterface heutiger Hochleistungsgrafikbeschleuniger ist 128
Bit breit, da jedoch sogenanter DDR Speicher verwendet wird, wird in 256
Bit Stücken auf den Speicher zugegriffen. Breiter wäre zwar besser,
da mehr Bandbreite zur Verfügung stände, aber auch teurer, da extra
Leitungen verlegt werden müssten und somit der Grafikkartenpreis ansteigen
würde. Also ließ man den Bus 128 Bit breit. Das Problem ist aber
ein anderes. Pro Speicherzugriff müssen die gesamten 256 Bit übertragen
werden. Wenn der GPU jetzt nur 64 Bit Daten benötigt, dann müssen
die restlichen 192 Bit mit Dummy-Bits gefüllt werden. Bei jedem noch
so kleinem Speicherzugriff werden also immer 256 Bit übertragen. Die
Effizienz liegt also oft nur bei rund 25 %. Der Crossbar Memory Kontroller
hilft hier gewaltig. Er besteht aus vier 64 Bit Kontrollern, die zusammen
256 Bit übertragen können, aber zusätzlich, bei kleineren
Packeten, nur 64 Bit übertragen. Somit steigt die Effizienz auf bis zu
100 % an.
verlustfreie Z-Daten Kompression(4:1)
Z-Daten machen eine großen Teil der beanspruchten Bandbreite aus.
Hierzu eine kleine Rechnung, die verdeutlicht, wieviel Prozent der Speicherbandbreite
von den Z-Daten benötigt werden:
RZ - Z-Daten aus dem Z-Buffer lesen WZ - Z-Daten in den Z-Buffer schreiben RC - Farbwert aus dem Framebuffer lesen (zwecks Alpha-Test) WC - Farbwert in den Framebuffer schreiben TR - Texturepixel aus dem Speicher lesen jeweils 4 Byte, bei 32 Farbtiefe und 32 Bit Z-Buffer (24 Bit Z-Daten / 8Bit Stencil Daten, denn es können nicht nur 24 Bit gelsesen werden!)
Z-Occulsion Culling
Durch einen frühzeitigen Z-Test wird versucht, zu bestimmen, ob ein Pixel sichtbar ist, oder nicht. Dies wird durch eine Front-to-Back (von vorne nach hinten) Sortierung begünstigt, die allerdings vom Programmiere zu erledigen, was bei heutigen CPU's kein Problem mehr darstellt, da viele 3D-Engines die Szenen nach Objekten sortieren, welche dann von vorne nach hinten geziechnet werden. Bei ATI nennt sich eine ähnliche Technik Hierarchical Z-Buffer (HZ buffer). Auf der Grafik kann man sehen, wo der Z-Test (HZ buffer) in der Pipeline ansetzt. 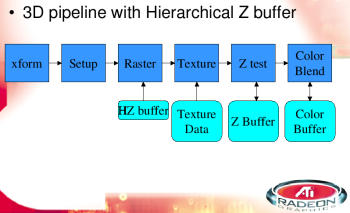
Eine weitere Methode, allerdings nur bei NVIDIA, nennt sich Occulsion Query
(Verdeckungs-Anfrage). Hier ist allerdings auch der Programmierer gefragt.
Er sendet Koordinaten einer Bounding-Box (Box, welche ein 3D-Objekt umgibt)
an den GPU, der überprüft dann, ob alle Pixel sichtbar sind
oder nicht und danach wird dann entschieden ob ein Objekt zur Grafikkarte
gesendet werden muss.
Higher Order Surface
Über Higher Order Surfaces (Oberflächen höherer Ordnung) könnte man einen ganzen Artikel schreiben, dies habe ich vor einiger Zeit auch getan. Eine Link gibts hier . Der Vorteil von HOS ist, dass man nur Kontrollpunkte an den GPU übertragen muss und der GPU daraus dann Flächen mit vielen hunderten Dreiecken errechnet. Dies spart enorm AGP-Bus Bandbreite, da nicht für jedes Dreieck Vertexdaten zu übertragen sind. 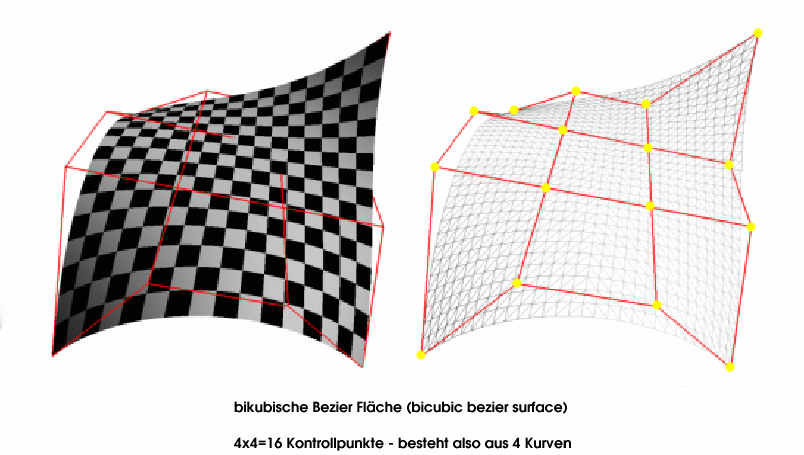
|